Hadoop集群搭建
1 机器准备说明(3台均为centos7)
主机名(机器)|ip|说明
-
hadoop-master 192.168.2.10 主节点 hadoop-node1 192.168.2.20 节点1 hadoop-node2 192.168.2.30 节点2
#3台均配置hosts
192.168.2.10 hadoop-master
192.168.2.20 hadoop-node1
192.168.2.30 hadoop-node2
2 关闭防火墙并设置hadoop-master免登录访问两个node节点
- 3台机器均关闭防火墙
#hosts
systemctl stop firewalld
systemctl disable firewalld
- hadoop-master执行以下命令设置免登录
ssh-keygen -t rsa (一路默认回车即可)
ssh-copy-id hadoop-master
ssh-copy-id hadoop-node1
ssh-copy-id hadoop-node2
3 下载软件安装包到hadoop-master(master上先配置好配置文件然后同步到node节点)
- hadoop-master及两个node软件安装包
hadoop-3.3.0.tar.gz
jdk-8u151-linux-x64.tar.gz
- 3台机均解压安装jdk及hadoop并配置环境变量,
vi /etc/profile配置以下环境变量
export JAVA_HOME=/software/jdk1.8.0_151
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/software/hadoop-3.3.0
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
- 安装完成后检查jdk及hadoop版本
[root@hadoop-master software]# java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
[root@hadoop-master software]# hadoop version
Hadoop 3.3.0
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r aa96f1871bfd858f9bac59cf2a81ec470da649af
Compiled by brahma on 2020-07-06T18:44Z
Compiled with protoc 3.7.1
From source with checksum 5dc29b802d6ccd77b262ef9d04d19c4
This command was run using /software/hadoop-3.3.0/share/hadoop/common/hadoop-common-3.3.0.jar
[root@hadoop-master software]#
4 配置hadoop对应配置文件(目录/software/hadoop-3.3.0/etc/hadoop)
- 配置
core-site.xml
<configuration>
<!--HDFS的NameService节点URL地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:8020</value>
</property>
<!-- Hadoop的运行时文件存放路径,如果不存在此目录需要格式化 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/software/hadoop-3.3.0/tmp</value>
</property>
<!-- HDFS高可用配置的Zookeeper地址(暂不配置)
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-master:2181</value>
</property>-->
</configuration>
- 配置
hadoop-env.sh中的JAVA_HOME
export JAVA_HOME=/software/jdk1.8.0_151
- 配置
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-node1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/var/data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/var/data/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop-master:8084</value>
</property>
</configuration>
- 配置
workers配置文件
hadoop-master
hadoop-node1
hadoop-node2
- 配置好hadoop-master的文件后需同步配置文件到两个node节点
cd /software/hadoop-3.3.0/etc/hadoop
scp -r core-site.xml hadoop-env.sh hdfs-site.xml workers root@hadoop-node1:/software/hadoop-3.3.0/etc/hadoop
scp -r core-site.xml hadoop-env.sh hdfs-site.xml workers root@hadoop-node2:/software/hadoop-3.3.0/etc/hadoop
5 配置启动及停止脚本并同步
start-dfs.sh及stop-dfs.sh增加以下配置
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh及stop-yarn.sh增加以下配置
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 同步
hadoop-master配置文件到两个node节点
cd /software/hadoop-3.3.0/sbin
scp -r start-dfs.sh start-yarn.sh stop-dfs.sh stop-yarn.sh root@hadoop-node1:/software/hadoop-3.3.0/sbin
scp -r start-dfs.sh start-yarn.sh stop-dfs.sh stop-yarn.sh root@hadoop-node2:/software/hadoop-3.3.0/sbin
6 格式化NameNode同时启动hadoop并检查
hadoop-master上执行以下命令完成格式化
hdfs namenode -format
hadoop-master上执行以下命令完成hadoop启动
start-all.sh
启动成功后jps可查看到对应进程
7 运行一个简单案例
-
启动成功后可使用
http://192.168.2.10:8084/dfshealth.html#tab-overview访问查看hadoop详情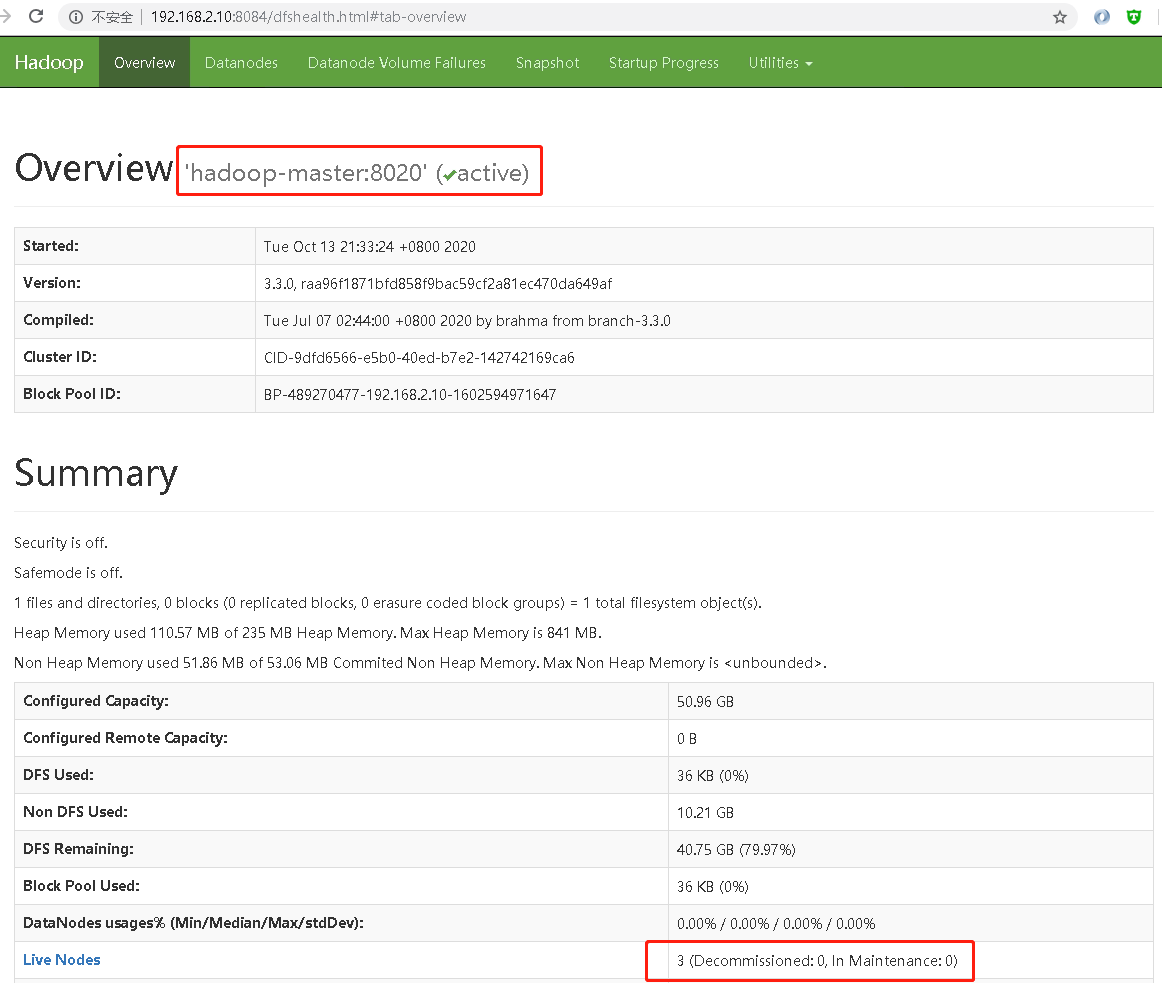
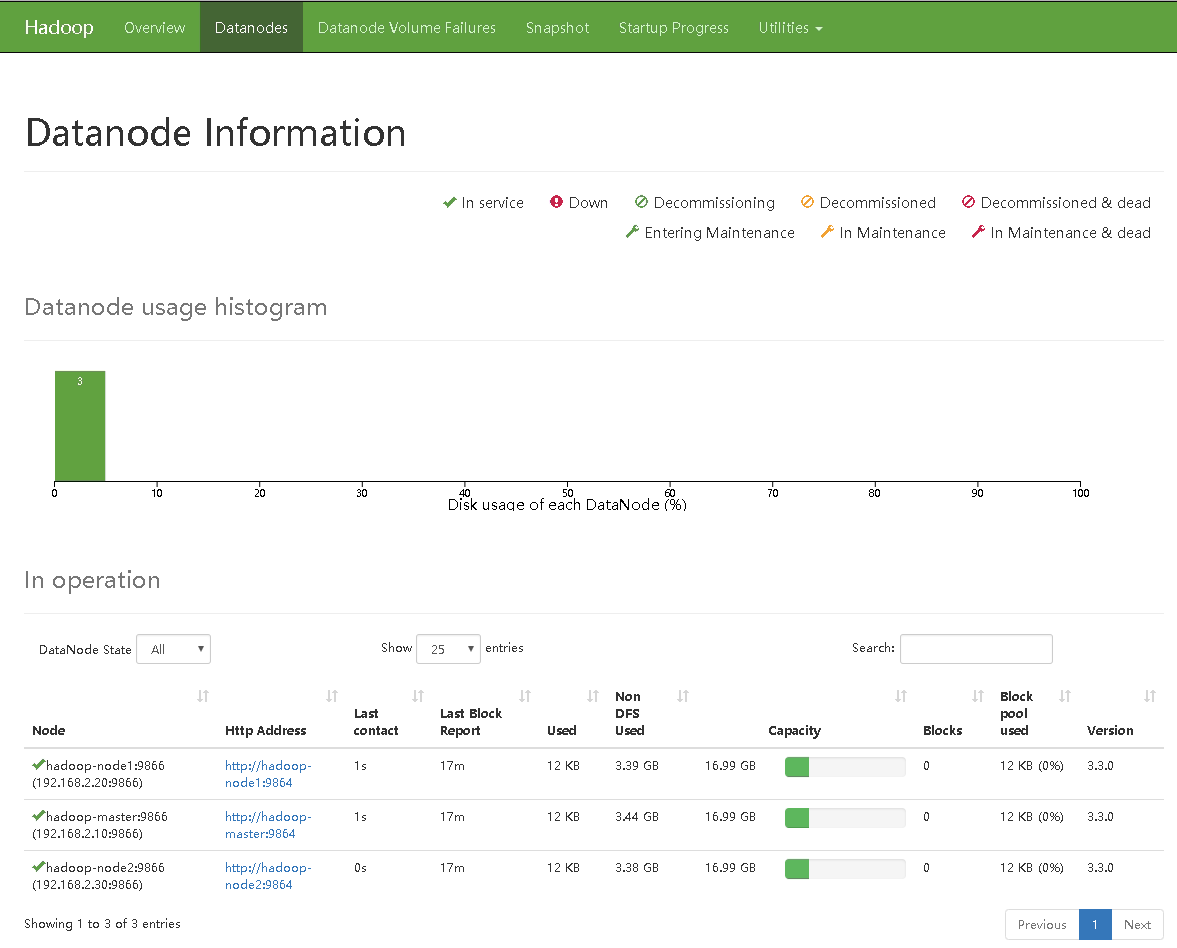
-
建立两个测试目录source及target
[root@hadoop-master hadoop]# hdfs dfs -mkdir /source
[root@hadoop-master hadoop]# hdfs dfs -mkdir /target
[root@hadoop-master hadoop]#
- 目录建立成功后,可以看到目录文件系统
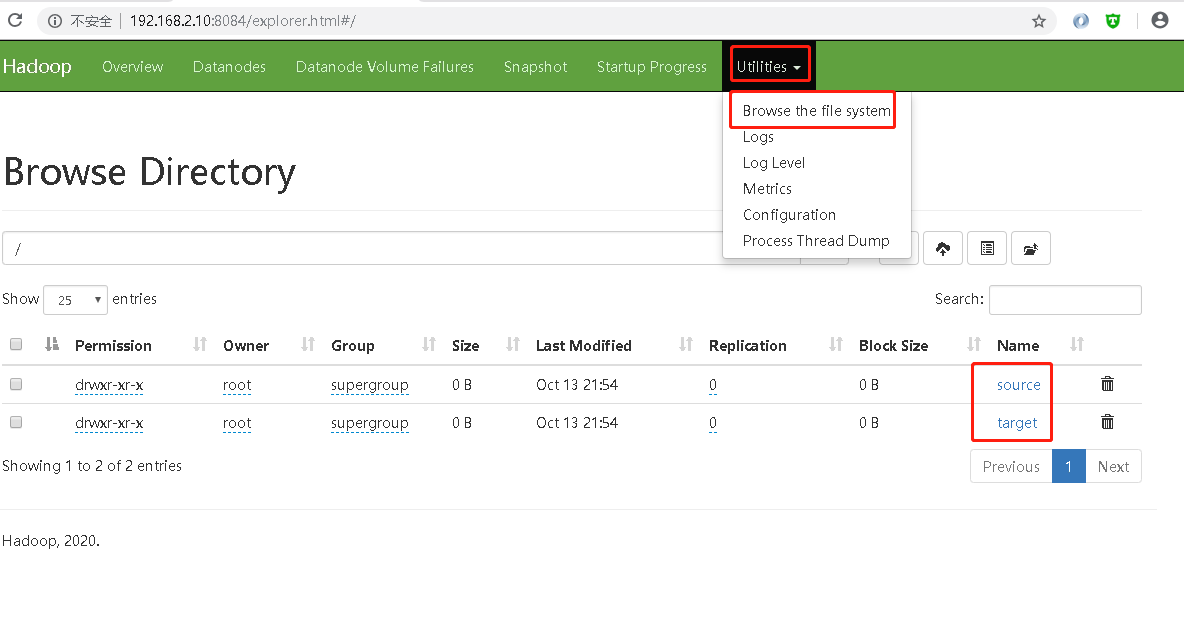
- 准备一段文字,我们摘取hadoop官网介绍,保存为
hadoop.txt
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
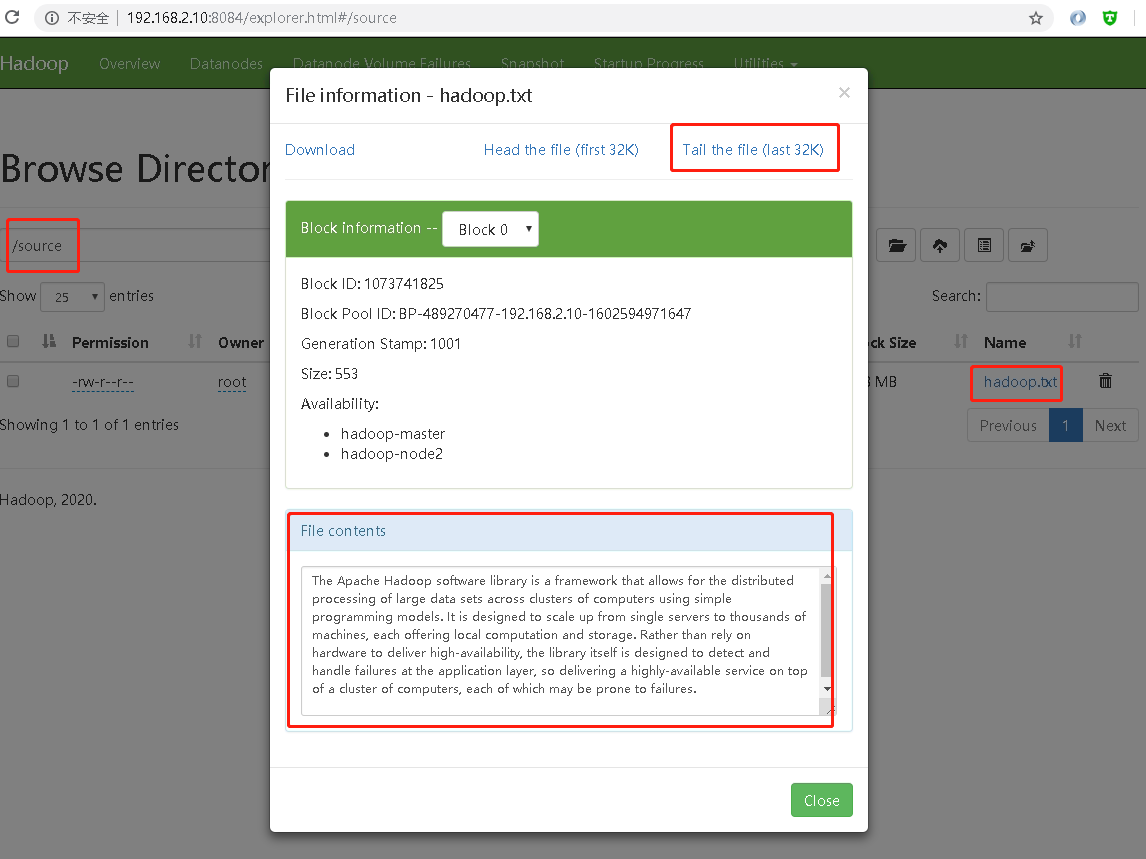
- 将
hadoop.txt文件上传到hdfs
[root@hadoop-master ~]# hdfs dfs -put hadoop.txt /source/hadoop.txt
[root@hadoop-master ~]#
- 上传文件后可通过管理后台查看文件,需访问机器需同样配置host
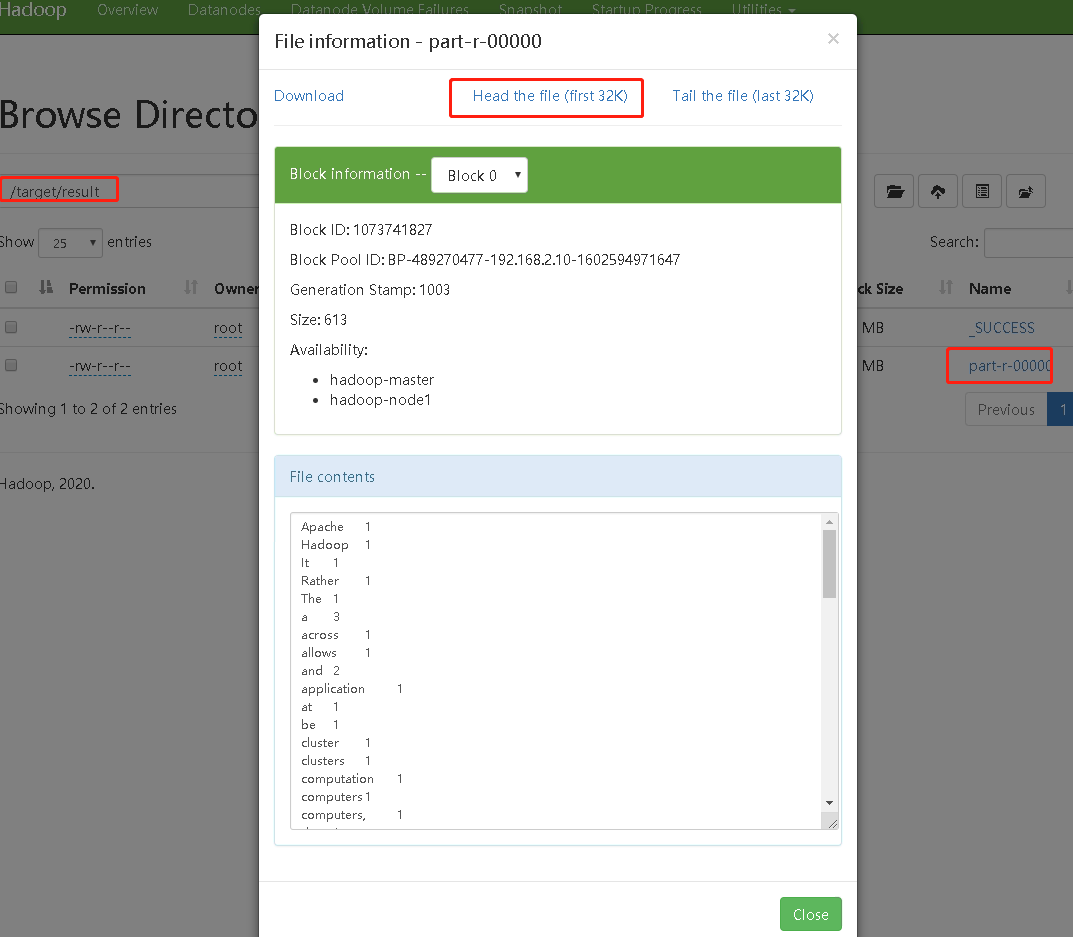
- 执行一个简单的mapreduce任务将
hadoop.txt单词统计信息输出
[root@hadoop-master ~]# hadoop jar /software/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /source/hadoop.txt /target/result
赞赏(Donation)
微信(Wechat Pay)
